Building Scrob: A Self-Hosted Music Scrobbling Server
I wanted to track what music I listen to without sending that data to Last.fm. Part privacy preference, part self-hosting habit.
So I set up scrob - a self-hosted scrobbling server that tracks my listening history and makes it shareable.
How It Works
Scrob is a REST API server with a separate static UI:
Music Player (shelltrax, etc.)
|
v
[POST /scrob] with Bearer token
|
v
Scrob API (Axum + Rust)
|
v
PostgreSQL (scrobbles + users)
|
v
Scrob UI (static Svelte site)
|
v
Public profile: ui.scrob.example.com/username
The server authenticates clients via Bearer tokens, stores scrobbles in Postgres, and serves stats via REST endpoints. The UI is a static site that fetches data from the API.
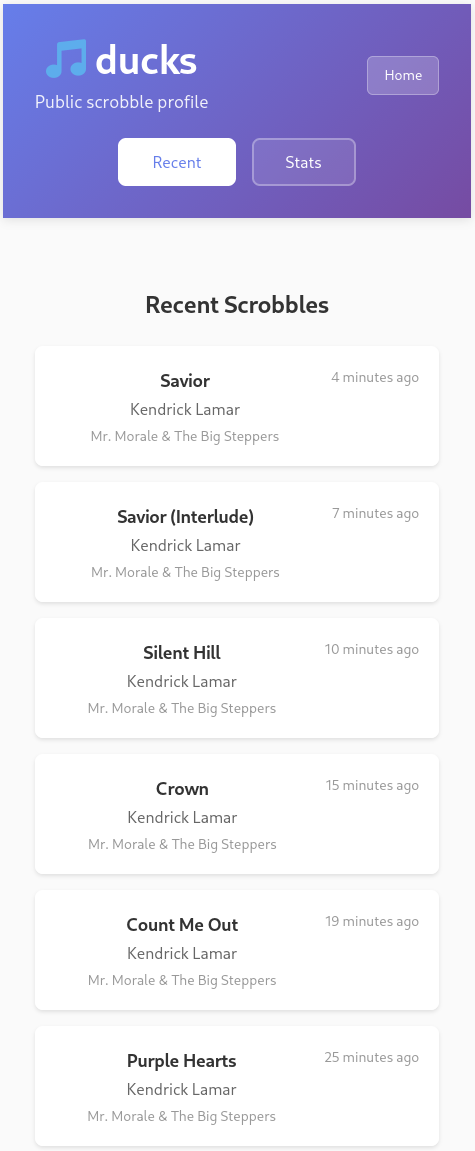
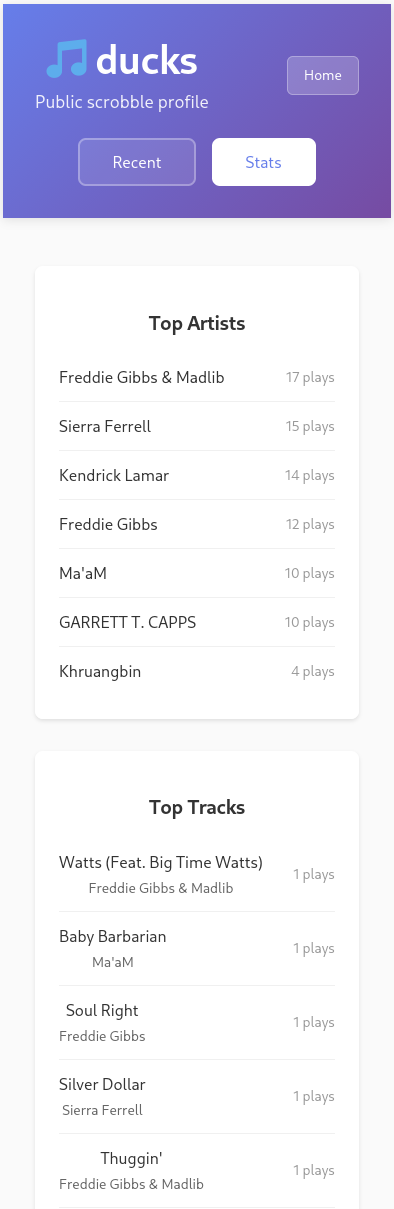
Public Profiles
The interesting part was adding public user profiles. Like Last.fm, I
wanted people to be able to share their music taste via a URL:
ui.scrob.jakegoldsborough.com/username
This required:
- New public API endpoints (
/users/:username/recent,/users/:username/top/artists,/users/:username/top/tracks) - Privacy controls (users are public by default, can opt-in to private)
- URL-based routing in the Svelte app
The privacy model is simple: a boolean is_private column in the users
table. Public endpoints check the flag and return 403 if private. Users
can toggle it via /settings/privacy.
Security Model
Scrob uses token-based authentication:
- Login with username/password to get a Bearer token
- All scrobble submissions require
Authorization: Bearer <token> - Tokens are stored in the database with revocation support
- Passwords are hashed with bcrypt
TLS is expected to be handled by a reverse proxy (Caddy, nginx, etc.). The server itself runs over HTTP.
Rate limiting is not currently implemented. Future work.
The Stack
Backend: Rust + Axum + PostgreSQL + sqlx
Frontend: Svelte 5 + Vite + TypeScript
Client: Shelltrax (my terminal music player)
Infrastructure: Systemd services on a VPS, no Docker
Scrob is straightforward. It's an API server that receives scrobble data, stores it in Postgres, and serves it back via REST endpoints. The UI is a static site that shows your listening history.
Try It
If you want to run your own scrob instance:
- Prerequisites: Rust 1.82+, PostgreSQL 12+, reverse proxy for TLS
- Clone repo and build:
cargo build --release - Set
DATABASE_URLenvironment variable - Migrations run automatically on first startup via
sqlx::migrate!() - Create a user with
./scripts/bootstrap.sh - Start UI (separate repo: scrob-ui) or use API directly
See the README for full details.
sqlx and Offline Query Caching
Scrob uses sqlx for compile-time checked SQL queries. This is great for type safety but annoying for CI: you need a database to compile.
The solution is cargo sqlx prepare which generates a .sqlx/ cache of
query metadata. Then CI can build with SQLX_OFFLINE=true without
needing Postgres.
The problem: running cargo sqlx prepare manually is tedious. You need
to spin up Postgres, run migrations, prepare the cache, tear it down.
I automated it with a Makefile:
prepare:
@docker run postgres:16-alpine (port 5433)
@Wait for postgres
@cargo sqlx migrate run
@cargo sqlx prepare
@docker rm postgres
Now make prepare handles everything. One command, query cache updated.
Dev Tooling
The prepare target must be rerun whenever you:
- Add or modify SQL queries in the codebase
- Create new migrations
- Change database schema
Without updating .sqlx/, CI builds fail with query verification
errors. The cache is committed to git, so offline builds work without a
live database connection.
Deployment
The deployment setup is declarative:
- Migrations live in the scrob repo
- On startup, scrob automatically detects and runs new migrations via
sqlx::migrate!() - The deploy script checks GitHub releases for new versions and only downloads if there's an update
- Systemd restarts the service after updating the binary
No manual migration management. No separate migration runner. Single source of truth.
What Works
- Scrobbling from Shelltrax to the API
- Public profile pages with recent scrobbles and top stats
- Privacy toggle (public by default, opt-in private)
- Automated migrations on startup
- Version-aware deployment script
What Doesn't
- No album stats yet (just artists and tracks)
- No client/player tracking (can't tell if you scrobbled from Shelltrax vs another client)
- Limited metadata (no album art, genre tags, etc.)
- UI is functional but basic
Reflections
The best part of this project was the deployment automation. The make prepare command and the version-checking deploy script make updates
trivial. Push a tag, wait for CI, run sudo ./bin/deploy, done.
Scrob isn't trying to compete with Last.fm's features... yet. It's a simple, self-hosted alternative that does one thing: tracks what you listen to and makes it shareable.
That's enough for now.